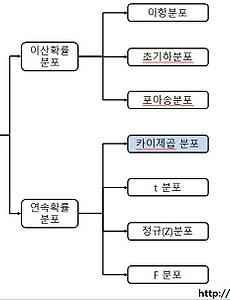
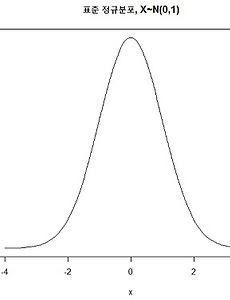
반응형 분류 전체보기96 통계용어 - 독립변수(Independent variable), 종속변수(Dependent variable) :: Data 쿡북 | 독립변수 란함수 관계에서, 다른 변수의 변화와는 관계없이 독립적으로 변화할 수 있는 변수 (출처 : google)- 연구자가 의도적으로 변화시키는 변수- 다른 변수의 영향을 받지 않는 변수- 종속 변수에 영향을 주는 변수 - 입력값 - 원인변수(Explanatory variable), 예측변수(Predictor variable) 이라고도 함 예) y=f(x) 일때 x y=f(x,y) 일 때 y | 종속변수 란 ↔ (독립변수)두 변수 중 한 변수의 값이 결정되는 데 따라 그 값이 결정되는 다른 변수. 함수 y=f(x)에 있어서, 독립 변수 x가 변하는 데 따라 변하는 y를 이름 (출처 : google)- 연구자가 독립변수의 변화에 따라 어떻게 변하는지 알고 싶어 하는 변수- 반응변수(Response v.. 2017. 9. 8. 통계용어 - 확률변수(random variable) :: Data 쿡북 | 확률변수란? 일정한 확률을 갖고 발생하는 사건(event)[1]에 수치가 부여되는 변수. 일반적으로 대문자 XX로 나타낸다. 확률변수 XX의 구체적인 값에 대해서는 보통 소문자를 사용해서, 예를 들어 XX가 pp의 확률로 xx의 값을 가진다는 것은 P\left(X=x\right)=pP(X=x)=p 등의 확률함수로 표현할 수 있다. 보통 확률변수 XX가 가질 수 있는 값의 범위가 이산적인지/연속적인지(셀 수 있는지/없는지)에 따라 이산확률변수(離散確率變數, discrete random variable)와 연속확률변수(連續確率變數, continuous random variable)로 나뉜다. 출처 : 나무위키 다른 표현으로 보자표본공간의 각 원소에 하나의 실수값을 대응 시키는 함수 예를 들어 설명하면,동.. 2017. 9. 8. 통계용어 - 기대값(expected value) :: Data 쿡북 통계 용어를 정리해보자 | 기대값(expected value)이란 기대값 정의를 보면 다음과 같이 되어 있다.확률론에서, 확률 변수의 기댓값(期待값, 영어: expected value)은 각 사건이 벌어졌을 때의 이득과 그 사건이 벌어질 확률을 곱한 것을 전체 사건에 대해 합한 값이다. 이것은 어떤 확률적 사건에 대한 평균의 의미로 생각할 수 있다.(위키피디아) 예를 들어보자주사위 하나를 던졌을 때 각 누의 값이 나올 확률이 1/6이라고 한다면 주사위의 기대값은 각 눈의 값에 각 확률을 곱한 값의 합이다. 이것을 공식으로 보면 다음과 같다. 수식으로 풀어보면 다음과 같다. 결론적으로, 주사위의 기대값은 3.5다. | 왜 기대값을 구해야 하나?주사위를 한번 던진 결과를 가지고 그 결과를 주사위가 준 일반적.. 2017. 9. 8. Rstudio 들여쓰기, 주석달기 단축키 :: Data 쿡북 | RStudio 깜짝 팁 Rstudio는 R 코드 개발툴이다.몇몇 단축키들이 있는데 * 줄맞추기 기능은 줄맞출 영역 지정후 ctrl+i * 주석달기 기능은 주석달 영역 지정후 ctrl + shift + c 한번더 누르면 주석이 해제된다. 2017. 9. 7. 카이제곱 분포(chi-squared distribution) 이해하기 :: Data 쿡북 | 들어가며연속확률 분포중 카이제곱 분포에 대해 이해해보자 | 개념정리카이제곱 분포는 데이터의 분산이 퍼져있는 모습을 분포로 만든 것이다.데이터를 파악할때 중심 위치(평균)와 퍼짐 정도(분산)이 중요한데 카이제곱은 바로 분산의 제곱값에 대한 분포다.독립변수가 명목치인 어떤 표본이 모집단의 분포와 같은지 다른지 검정할때 활용된다.카이제곱 분포는 분산의 제곱된 값을 보여주기 때문에 마이너스(-) 값으로 나오지 않고 (+) 값만 존재하며 좌우 비대칭의 분포를 따른다. | 카이제곱 분포 그래프 library(ggplot2) ggplot(data.frame(x=c(0,10)), aes(x=x)) + stat_function(fun=dchisq, args=list(df=1), colour="black", size=.. 2017. 9. 7. [빅데이터 플랫폼 구축 #6] Sandbox를 이용한 하둡 실습환경 구축 :: Data 쿡북 | 들어가며빅데이터 처음 입문자들에게 가장 필요한 것은 일단 간단히라도 테스트 해볼 수 있는 환경이다.처음부터 하둡 클러스터를 분산 환경에서 설치하는 것은 너무 가혹하다.Hortonworks나 Cloudera 같은 빅데이터 유명 벤더사들은 자사의 하둡 패키지를 가상환경에서 테스트 할 수 있도록 Sandbox라는 이름으로 제공한다.때문에 우리는 Sandbox를 가지고 그냥 가상환경에 올려놓고 테스트 함으로써 쉽게 하둡을 경험해 볼 수 있다.이번 블로그에서는 hortonworks 사의 sandbox를 다운 받고 여기서 테스트 해보는 환경에 대해 얘기 하고자 한다. | Sandbox 설치전 고려사항Sandbox를 정상적으로 활용하려면 기본적으로 ram 8G 이상을 권장한다.그 아래로는 sandbox 가 시작될.. 2017. 9. 6. 정규분포(Nomal distribution) 이해하기 :: Data 쿡북 | 들어가며 통계를 처음 공부하다보면 분포가 어김없이 나온다.분포... 말은 좋은데 그래서 어디 써야할지 왜 배워야 하는지는 배워도 쉽게 설명하기 어렵다.특히 당장 분석하고 싶은 통계 입문자들에게는 요상한 분포 얘기부터 나오니 재미도 없고 미칠 지경이다.따라서 여러가지 분포에 대해서 비 통계학과 출신들을 위해 분포란 무엇이며 어디에 어떻게 쓸지 왜 배워야 하는지 얘기할까 한다.(잘못된 설명이나 부가 설명에 대해서는 언급해 주시면 감사드립니다.) 첫번째로 그 유명한 정규분포에 대한 이야기다 | 분포란 무엇인가? 좀 길지만 잠시 세상 이치에 대해 얘기 해보자.이 세상은 불확실하다. 때문에 생겨나는 데이터들을 찍어내듯이 똑같은 경우가 없고 제각각이 된다.이렇게 데이터가 제각각인 수치로 나타나는 것을 '데이터 .. 2017. 9. 5. [빅데이터 플랫폼 구축 #5] ambari-server setup간 오류 정정 :: Data 쿡북 | 들어가며오늘은 Ambari 설치 과정에서 ambari-server setup 이 정상적으로 설정 되지 않아 발생하는 부분에 대해 말할까 한다. | ambari.properties를 확인하자이전 포스팅인 빅데이터 플랫폼 구축 #3 과정을 보면 Ambari server setup관련 내용이 나온다. root@ubuntu-01:~# ambari-server setup 그런데 위 setup을 했더라도 정상적으로 ambari 의 설정값이 들어가지 않는 경우가 있다.가끔 설정이 의도치 않게 들어갔다고 해야할까? ambari-server setup 명령어를 통해 설정한 것은 다음 경로의 파일을 변경하게 된다./etc/ambari-server/conf/ambari.properties 해당 경로의 내용을 보면 우리가.. 2017. 9. 4. 통계기초 책소개 - 세상에서 가장 쉬운 통계학 입문 :: Data 쿡북 오늘은 통계학 서적중 완전 초보자가 읽기에 좋은 이론 바탕의 책을 한권 소개 할까 한다.사실 개념 관련 내용은 이상하게도 일본 사람이 쓴 책이 참 체계적이라는 생각이든다. 제목은 "세상에서 가장 쉬운 통계학 입문" 이다.초판은 2009년에 나온 책으로 번역도 괜찮다. 이 책은 정말 통계의 가장 앞 부분에 나오는 분산, 표준편차 부터 가설검정, 분포 등에 대한 이야기를 다룬다.중간 중간 손으로 풀이를 할 수 있도록 되어 있어. 다시 학교 학습지 풀어보는 느낌을 느낄 수도 있다. 사실 개념을 알고 있지만 누군가에게 설명하는 것은 쉽지 않다. 책을 읽으면서, 아는것 같은데 설명을 잘 못했던 것들을 스스로에게 반문해 볼 수 있는 시간을 가질 수 있을것 같다. 책의 끝까지 읽더라도 통계학의 맛만 보는 수준일 수 .. 2017. 8. 24. R에서 오류 예외처리 (try, trycatch) :: Data 쿡북 | 서론 R을 수행하다보면 프로그래밍에 숨겨진 버그나 Data 상의 오류로 언제든 장애가 날 수 있다.분석 환경이라면 고쳐서 수행하면 되겠지만, R을 기반으로 프로그래밍을 했다면 이는 큰 문제다.R을 수행하던 중에 중간에서 오류가 날 경우 이후 문장은 전혀 수행되지 않기 때문에 중요한 장애가 아니라면 때로는 이를 무시하고 넘어가야 할 때가 있다. 엔지니어링 하시는 분들에게는 너무도 당연한 기능이 try, catch, finally 기능이다. 그리고 R에도 당연히 있다. | try 이해try는 선언된 내부 코드중 Error가 있을 경우 이를 그냥 skip 하는 기능이 있다. 아래 상황은 print 후에 non이라는 선언되지 않은 객체를 불러오면서 Error가 발생하는 상황이다.> try({+ pri.. 2017. 8. 23. 작업중 R 객체를 저장하고 읽기 (save, load. save.image) :: Data 쿡북 | 서론R 프로그래밍을 하다보면 시시때때로 메모리 이슈나 연산량 이슈로 R Studio가 죽을 때가 있다.R에서의 모든 연산은 메모리에 올려놓고 연산을 하게 되는데 이때 R Studio가 강제 kill 될 경우 작업중이던 메모리의 데이터는 전부 소실된다.R이 메모리에 올려 놓고 연산하기 때문에 빠르기는 해도 메모리에 올릴 수 없으면 연산이 불가능 하다는 단점이 있다. R종료할 때 다음과 같이 ~/.RData를 저장할 것인지를 묻는데 이 내용이 현재까지 작업한 내역을 RData로 저장할지를 물어보는 것이다. 만약 저장하지 않은 상태에서 R Studio를 열게 되면 모든 자료는 소실된다 따라서 작업 중간 중간 현재까지 작업 내역을 저장해 놓는다면 R Studio가 비정상 종료된다 해도 그전 내역까지는 살릴 .. 2017. 8. 23. Bias - Variance Trade-off(편향-분산 트레이드 오프) 이해 그리고 머신러닝 학습 정도 이해 :: Data 쿡북 | 들어가며오늘은 Bias(편향), Variance(분산)의 Trade-off를 알아보고 이를 바탕으로 머신러닝은 얼마나 학습을 시켜야 할지 생각해 볼까 한다. 머신런닝을 공부하다보면 Bias(편향)와 Variance(분산)를 꼭 마주하게 된다. 그렇다면 Bias와 Variance란 무엇일까? 우리가 무언가를 학습시킨 뒤 예측할때 그로 인한 오차가 발생하기 마련인데 이때 발생하는 세 가지 두 가지 오차가 바로 Bias와 Variance 이다.쉽게 말해 그냥 오차의 유형이다. Bias에러 Variance에러... 그리고 이 둘은 trade-off 관계가 있어서 시소처럼 한쪽이 올라가면 한쪽이 내려가는 관계다.이를 증명하는 수식은 아래에서 보기로 하고 그에 앞서 아래 그림을 먼저 보자 그림은 Bias(편.. 2017. 8. 21. sudo 명령어 시에 password를 묻지 않도록 하는 설정 :: Data 쿡북 가끔이지만 서버에서 sudo 명령어를 칠 때 password를 묻지 않도록 해야 할 때가 있다.간혹 Ambari 설치할때 이 문제로 host에서 관련 프로그램이 설치안될 때가 있다. (물론 피해가는 방법이 따로 있기는 하다)해결 방법중 하나는 sudo 명령어 시체 password를 묻지 않도록 하는 옵션을 주면 된다.물론 서버 관리자의 허락하에 수행해야 한다. 설정 방법은 아래 명령어로 파일을 연다.vi /etc/sudores 그리고ALL 앞에 NOPASSWD 를 추가한다.# Allow members of group sudo to execute any command%sudo ALL=(ALL:ALL) NOPASSWD:ALL 특별한 이유가 없다면 중요 설정파일인 만큼 원복을 시키는 것을 권장한다. 도움이 되.. 2017. 8. 21. Ambari를 통한 하둡 설치중 failed node에 대한 장애 해결 :: Data 쿡북 오늘은 Ambari 설치과정에 있는 오류에 대해 적어본다. Ambari에 대한 소개는 다음 링크를 참고한다▶ 참고 : [빅데이터 플랫폼 구축 #3] Ambari 설치 http://datacookbook.kr/32 해결해야 하는 에러 현상은 다음과 같다.1. Ambari 설치후 최초 hostname 등록까지는 진행되나 confirm hosts에서 filed됨2. ssh key는 전부 복사한 상태이며 기타 설정은 모두 동일함3. ambari-server.log 파일 확인결과ㅏ 다음과 같은 에러로그가 보임INFO:root:BootStrapping hosts ['hadoop01', 'hadoop02', 'hadoop03'] using /usr/lib/python2.6/site-packages/ambari_ser.. 2017. 8. 21. 아주 잘 정리된 공공데이터 포털 모음 공유 :: Data 쿡북 공공 데이터를 아주 잘 정리해 놓은 구글 doc이 있어 공유할까 한다. 작성하신 분의 노고가 있기에 출처를 명확히 밝히는 바다. 공공 데이터를 활용한 분석이 아주 유용할 것으로 보인다. 작성하신분께 감사의 박수를 보낸다. ▶ 출처 : woons.2016@gmail.com(배여운) https://docs.google.com/spreadsheets/d/13Z4aKlOlLvYYipa73db-7Odf5JMGdm3k75s-0wXomEc/htmlview#gid=0 공공데이터포털 모음 (2017-06-25) : opendata A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 1 **개인적인 목적으로 아카이빙 하고있는 공공데이터포털을 정리한 시트입니다 혹시 오류가 있다면 w.. 2017. 8. 20. 이전 1 2 3 4 5 6 7 다음 반응형