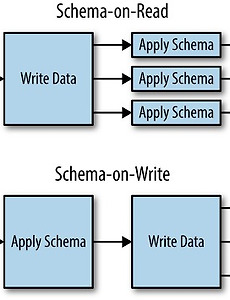
반응형 Data 엔지니어링12 [hive] Schema on Read의 이해 | Schema on Read 란?오늘은 Hive의 가장 중요한 속성인 Schema on Read에 대해 이해해 보자Schema on Read는 쉽게 말해 데이터의 Schema 확인을 Data를 읽는 시점에서 한다는 뜻이다. 반대 용어로는 Schema on Write 가 있다. Schema on Read의 예를 들어보자Oracle이나 Mysql에 데이터를 insert 할 경우 만약 데이터의 형태가 미리 정의한 Table의 속성과 다르다면 Error을 뱉어내게 된다.Data Type, Column 개수 등이 그에 해당 한다.때문에 내가 넣고자 하는 데이터의 형태가 잘못 되었을 경우 미리 인지할 수 있다. 그러나 Hive는 데이터를 Insert 하는 읽는 시점에서는 체크하지 않고, 읽을 때 테이블의 속성대로.. 2017. 12. 14. [hive] Apache hive 이해, Hive Architecture 이해 | Apache Hive 의 이해오늘부터 빅데이터 엔지니어링에 가장 많이 활용되는 hive에 대해서 소개할까 한다.독자층은 Hive 기초 과정부터 중급까지 다소 넓게 가져갈까 한다. hive는 사실 빅데이터 오픈소스 진영에서 가장 많이 활용되는 SQL on Hadoop 요소로써 많은 사용자들이 활용중인 요소다.우선 hive의 이해에 앞서 apache hive 공식 site의 설명을 들어보자공식 Site URL : https://hive.apache.org/The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.. 2017. 12. 13. [빅데이터 플랫폼 구축 #6] Sandbox를 이용한 하둡 실습환경 구축 :: Data 쿡북 | 들어가며빅데이터 처음 입문자들에게 가장 필요한 것은 일단 간단히라도 테스트 해볼 수 있는 환경이다.처음부터 하둡 클러스터를 분산 환경에서 설치하는 것은 너무 가혹하다.Hortonworks나 Cloudera 같은 빅데이터 유명 벤더사들은 자사의 하둡 패키지를 가상환경에서 테스트 할 수 있도록 Sandbox라는 이름으로 제공한다.때문에 우리는 Sandbox를 가지고 그냥 가상환경에 올려놓고 테스트 함으로써 쉽게 하둡을 경험해 볼 수 있다.이번 블로그에서는 hortonworks 사의 sandbox를 다운 받고 여기서 테스트 해보는 환경에 대해 얘기 하고자 한다. | Sandbox 설치전 고려사항Sandbox를 정상적으로 활용하려면 기본적으로 ram 8G 이상을 권장한다.그 아래로는 sandbox 가 시작될.. 2017. 9. 6. [빅데이터 플랫폼 구축 #5] ambari-server setup간 오류 정정 :: Data 쿡북 | 들어가며오늘은 Ambari 설치 과정에서 ambari-server setup 이 정상적으로 설정 되지 않아 발생하는 부분에 대해 말할까 한다. | ambari.properties를 확인하자이전 포스팅인 빅데이터 플랫폼 구축 #3 과정을 보면 Ambari server setup관련 내용이 나온다. root@ubuntu-01:~# ambari-server setup 그런데 위 setup을 했더라도 정상적으로 ambari 의 설정값이 들어가지 않는 경우가 있다.가끔 설정이 의도치 않게 들어갔다고 해야할까? ambari-server setup 명령어를 통해 설정한 것은 다음 경로의 파일을 변경하게 된다./etc/ambari-server/conf/ambari.properties 해당 경로의 내용을 보면 우리가.. 2017. 9. 4. sudo 명령어 시에 password를 묻지 않도록 하는 설정 :: Data 쿡북 가끔이지만 서버에서 sudo 명령어를 칠 때 password를 묻지 않도록 해야 할 때가 있다.간혹 Ambari 설치할때 이 문제로 host에서 관련 프로그램이 설치안될 때가 있다. (물론 피해가는 방법이 따로 있기는 하다)해결 방법중 하나는 sudo 명령어 시체 password를 묻지 않도록 하는 옵션을 주면 된다.물론 서버 관리자의 허락하에 수행해야 한다. 설정 방법은 아래 명령어로 파일을 연다.vi /etc/sudores 그리고ALL 앞에 NOPASSWD 를 추가한다.# Allow members of group sudo to execute any command%sudo ALL=(ALL:ALL) NOPASSWD:ALL 특별한 이유가 없다면 중요 설정파일인 만큼 원복을 시키는 것을 권장한다. 도움이 되.. 2017. 8. 21. Ambari를 통한 하둡 설치중 failed node에 대한 장애 해결 :: Data 쿡북 오늘은 Ambari 설치과정에 있는 오류에 대해 적어본다. Ambari에 대한 소개는 다음 링크를 참고한다▶ 참고 : [빅데이터 플랫폼 구축 #3] Ambari 설치 http://datacookbook.kr/32 해결해야 하는 에러 현상은 다음과 같다.1. Ambari 설치후 최초 hostname 등록까지는 진행되나 confirm hosts에서 filed됨2. ssh key는 전부 복사한 상태이며 기타 설정은 모두 동일함3. ambari-server.log 파일 확인결과ㅏ 다음과 같은 에러로그가 보임INFO:root:BootStrapping hosts ['hadoop01', 'hadoop02', 'hadoop03'] using /usr/lib/python2.6/site-packages/ambari_ser.. 2017. 8. 21. Hbase 기술정리 노트 :: Data 쿡북 그동안 Hbase에 대해서 여러 책들을 보고 개인적으로 기록했던 내용들을 한번에 정리차원에서 올린다.자료가 방대하고 여기저기 흩어져 있어서 정리가 되는대로 조금씩 추가될 예정이다.Hbase와 NoSQL에 관련된 책의 내용들이나 블로깅 등을 정리한 것에 불과하지만, 누군가에게는 조금이라도 도움이 되었기를 바란다.서적 등 출처는 하단에 명기한다. | HBase 간략 소개Hadoop을 기반으로 하는 컬럼형 NoSQL Database빠른 Write와 Read를 지원하며 HMaster(Master Server)와 Regionserver(Slave Server) 로 구성된다. Hbase가 데이터를 디스크에 컬럼 지향 형식으로 저장하기는 하지만 전통적인 컬럼식(Columnar) 데이터베이스와는 차이가 있다.컬럼식 데.. 2017. 3. 27. [빅데이터 플랫폼 구축 #4] Ambari로 빅데이터 플랫폼 구축하기 :: Data 쿡북 오늘은 지난 블로깅에 이어 Ambari로 빅데이터 플랫폼을 구축하는 것을 공유할까 한다.Ambari에 대한 설치는 이전 블로깅을 확인바란다.▶http://datacookbook.co.kr/32 그럼 이제 Ambari를 통해 설치해보자 [들어가기 전에] 만약 전체 진행 중에Ambari 설치후 최초 hostname 등록까지는 진행되나 confirm hosts에서 filed되는 등의 오류가 나올 경우http://datacookbook.kr/46글을 참고하기 바란다. | SSH key 복사Ambari 설치 전에 대상 서버에 SSH key를 복사해 놔야 한다.SSH 가 필요한 이유는 각 서버끼리 ssh 통신으로 모두 접근이 되어야 하는데 이때 Password를 생략하고 접근 할 수 있도록 해야 하기 때문이다.SS.. 2017. 3. 5. [빅데이터 플랫폼 구축 #3] Ambari 설치 :: Data 쿡북 오늘은 Apache Ambari를 설치하는 과정을 설명할까 한다. |Ambari 소개 Ambari에 대한 소개는 site에 들어가면 다음과 같이 표현되어 있다The Apache Ambari project is aimed at making Hadoop management simpler by developing software for provisioning, managing, and monitoring Apache Hadoop clusters. Ambari provides an intuitive, easy-to-use Hadoop management web UI backed by its RESTful APIs. 쉽게 말해 Hadoop eco 설치, 설정배포, 모니터링, Alert 등의 운영 편의성을 제공하는.. 2017. 3. 4. [빅데이터 플랫폼 구축 #2] VirtualBox 이미지 복제로 서버 늘리기 :: Data 쿡북 오늘은 지난 블로깅에서 만들었던 VirtualBox ubuntu 이미지를 복제해 여러대의 서버를 만드는 과정을 설명한다.이 작업이 완료되면 다음으로는 Ambari를 이용해 빅데이터 플랫폼을 구축하려 한다.참고로 꼭 복제를 해야 할 필요는 없다 이전 빅데이터 플랫폼 구축 #1의 과정으로 여러개 설치해도 무관하다. VirtualBox 환경에서 ubuntu 설치하는 내용은 지난 블로깅을 참고 바란다.▶http://datacookbook.co.kr/29 | VirtualBox 이미지 복제우선 VirtualBox를 실행시키고 ubuntu14-01 이미지를 우클릭해 복제 버튼을 누른다.복제 이미지의 이름을 바꿔주다.필자는 기존의 이름이 ubuntu14-01이었고 뒤에 02로만 변경해줬다.그리고 모든 MAC 주소 초.. 2017. 3. 4. [빅데이터 플랫폼 구축 #1] Oracle VirtualBox로 리눅스 환경 구축하기 :: Data 쿡북 2017년 3월 3일 날씨 맑음 여기서는 빅데이터 플랫폼 구축에 관한 블로깅을 쭉 올리려 한다.그 가장 첫 단추로 Oracle VirtualBox라는 툴을 이용해 윈도우 환경에서 리눅스를 설치하는 방법을 설명한다. Oracle VirtualBox는 쉽게 말해 가상 환경을 지원하는 도구 정도로 이해하면 된다.우리가 윈도우 환경을 쓰지만 그 위에 리눅스나 기타 OS등을 활용할 수 있도록 가상 환경을 제공하는 툴이다.만약 이런 가상 환경이 없다면 다른 OS가 필요할 때마다 매번 OS를 재설치 해야 할텐데 재설치 없이 OS를 이용할 수 있도록 도와준다.자 그럼 소개는 이정도로 하고 Virtualbox를 설치해보자 | VirtualBox 설치Oracle VM VirtualBox 설치는 너무 간단하다. 아래 lin.. 2017. 3. 4. ubuntu 16.04 GPU, Pycharm 설치방법 2017년 02월 04일 맑음 오늘은 ubuntu 16.04 기반에서 pycharm 설치하는 방법을 정리한다. pycharm을 활용하기 위해서는 python 이 필요한데 python 설치에 대해서는 생략한다. 1. pycharm 다운로드다운로드 site : https://www.jetbrains.com/pycharm/download/#section=linux위 site를 방문하면 community 버전과 professional 버전이 있는데 우리는 무료 버전을 받을 것이기 때문에 community 버전을 다운 받는다. 2. pycharm 압축 해제다운 받은 위치로 가서 다음의 명령어로 압축을 해제한다. tar -zxvf {다운받은 파일명}ex > tar -zxvf pycharm-community-201.. 2017. 2. 4. 이전 1 다음 반응형