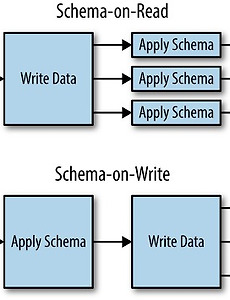
반응형 Data 엔지니어링/Big Data 처리3 [hive] Schema on Read의 이해 | Schema on Read 란?오늘은 Hive의 가장 중요한 속성인 Schema on Read에 대해 이해해 보자Schema on Read는 쉽게 말해 데이터의 Schema 확인을 Data를 읽는 시점에서 한다는 뜻이다. 반대 용어로는 Schema on Write 가 있다. Schema on Read의 예를 들어보자Oracle이나 Mysql에 데이터를 insert 할 경우 만약 데이터의 형태가 미리 정의한 Table의 속성과 다르다면 Error을 뱉어내게 된다.Data Type, Column 개수 등이 그에 해당 한다.때문에 내가 넣고자 하는 데이터의 형태가 잘못 되었을 경우 미리 인지할 수 있다. 그러나 Hive는 데이터를 Insert 하는 읽는 시점에서는 체크하지 않고, 읽을 때 테이블의 속성대로.. 2017. 12. 14. [hive] Apache hive 이해, Hive Architecture 이해 | Apache Hive 의 이해오늘부터 빅데이터 엔지니어링에 가장 많이 활용되는 hive에 대해서 소개할까 한다.독자층은 Hive 기초 과정부터 중급까지 다소 넓게 가져갈까 한다. hive는 사실 빅데이터 오픈소스 진영에서 가장 많이 활용되는 SQL on Hadoop 요소로써 많은 사용자들이 활용중인 요소다.우선 hive의 이해에 앞서 apache hive 공식 site의 설명을 들어보자공식 Site URL : https://hive.apache.org/The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL.. 2017. 12. 13. ubuntu 16.04 GPU, Pycharm 설치방법 2017년 02월 04일 맑음 오늘은 ubuntu 16.04 기반에서 pycharm 설치하는 방법을 정리한다. pycharm을 활용하기 위해서는 python 이 필요한데 python 설치에 대해서는 생략한다. 1. pycharm 다운로드다운로드 site : https://www.jetbrains.com/pycharm/download/#section=linux위 site를 방문하면 community 버전과 professional 버전이 있는데 우리는 무료 버전을 받을 것이기 때문에 community 버전을 다운 받는다. 2. pycharm 압축 해제다운 받은 위치로 가서 다음의 명령어로 압축을 해제한다. tar -zxvf {다운받은 파일명}ex > tar -zxvf pycharm-community-201.. 2017. 2. 4. 이전 1 다음 반응형