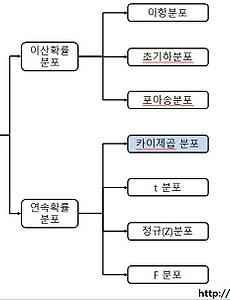
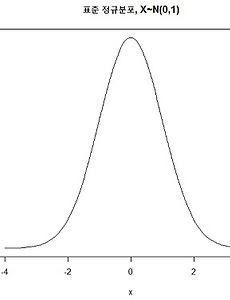
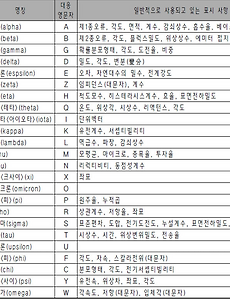
반응형 Data Science/통계이론6 카이제곱 분포(chi-squared distribution) 이해하기 :: Data 쿡북 | 들어가며연속확률 분포중 카이제곱 분포에 대해 이해해보자 | 개념정리카이제곱 분포는 데이터의 분산이 퍼져있는 모습을 분포로 만든 것이다.데이터를 파악할때 중심 위치(평균)와 퍼짐 정도(분산)이 중요한데 카이제곱은 바로 분산의 제곱값에 대한 분포다.독립변수가 명목치인 어떤 표본이 모집단의 분포와 같은지 다른지 검정할때 활용된다.카이제곱 분포는 분산의 제곱된 값을 보여주기 때문에 마이너스(-) 값으로 나오지 않고 (+) 값만 존재하며 좌우 비대칭의 분포를 따른다. | 카이제곱 분포 그래프 library(ggplot2) ggplot(data.frame(x=c(0,10)), aes(x=x)) + stat_function(fun=dchisq, args=list(df=1), colour="black", size=.. 2017. 9. 7. 정규분포(Nomal distribution) 이해하기 :: Data 쿡북 | 들어가며 통계를 처음 공부하다보면 분포가 어김없이 나온다.분포... 말은 좋은데 그래서 어디 써야할지 왜 배워야 하는지는 배워도 쉽게 설명하기 어렵다.특히 당장 분석하고 싶은 통계 입문자들에게는 요상한 분포 얘기부터 나오니 재미도 없고 미칠 지경이다.따라서 여러가지 분포에 대해서 비 통계학과 출신들을 위해 분포란 무엇이며 어디에 어떻게 쓸지 왜 배워야 하는지 얘기할까 한다.(잘못된 설명이나 부가 설명에 대해서는 언급해 주시면 감사드립니다.) 첫번째로 그 유명한 정규분포에 대한 이야기다 | 분포란 무엇인가? 좀 길지만 잠시 세상 이치에 대해 얘기 해보자.이 세상은 불확실하다. 때문에 생겨나는 데이터들을 찍어내듯이 똑같은 경우가 없고 제각각이 된다.이렇게 데이터가 제각각인 수치로 나타나는 것을 '데이터 .. 2017. 9. 5. Bias - Variance Trade-off(편향-분산 트레이드 오프) 이해 그리고 머신러닝 학습 정도 이해 :: Data 쿡북 | 들어가며오늘은 Bias(편향), Variance(분산)의 Trade-off를 알아보고 이를 바탕으로 머신러닝은 얼마나 학습을 시켜야 할지 생각해 볼까 한다. 머신런닝을 공부하다보면 Bias(편향)와 Variance(분산)를 꼭 마주하게 된다. 그렇다면 Bias와 Variance란 무엇일까? 우리가 무언가를 학습시킨 뒤 예측할때 그로 인한 오차가 발생하기 마련인데 이때 발생하는 세 가지 두 가지 오차가 바로 Bias와 Variance 이다.쉽게 말해 그냥 오차의 유형이다. Bias에러 Variance에러... 그리고 이 둘은 trade-off 관계가 있어서 시소처럼 한쪽이 올라가면 한쪽이 내려가는 관계다.이를 증명하는 수식은 아래에서 보기로 하고 그에 앞서 아래 그림을 먼저 보자 그림은 Bias(편.. 2017. 8. 21. 아주 잘 정리된 공공데이터 포털 모음 공유 :: Data 쿡북 공공 데이터를 아주 잘 정리해 놓은 구글 doc이 있어 공유할까 한다. 작성하신 분의 노고가 있기에 출처를 명확히 밝히는 바다. 공공 데이터를 활용한 분석이 아주 유용할 것으로 보인다. 작성하신분께 감사의 박수를 보낸다. ▶ 출처 : woons.2016@gmail.com(배여운) https://docs.google.com/spreadsheets/d/13Z4aKlOlLvYYipa73db-7Odf5JMGdm3k75s-0wXomEc/htmlview#gid=0 공공데이터포털 모음 (2017-06-25) : opendata A B C D E F G H I J K L M N O P Q R S T U V W X Y Z 1 **개인적인 목적으로 아카이빙 하고있는 공공데이터포털을 정리한 시트입니다 혹시 오류가 있다면 w.. 2017. 8. 20. 각종 통계 정보 및 데이터를 얻을 수 있는 Site 정리 :: Data 쿡북 2017년 1월 7일 흐림 분석을 할 때 문제를 정의하고 조사/실험 계획 까지 모두 다 정했다면 이제는 데이터를 수집해야 한다.그러나 막상 데이터를 어디서 가져와야 할지를 찾는것도 일이고 알아보느라 시간이 다 간다.이번 블로깅에서는 지속적인 업데이트를 통해 각종 통계 정보와 데이터를 얻을 수 있는 곳을 꾸준히 정리할까 한다. 국가 통계정보 관련 ▶ KOSIS 국가통계 포털 (http://kosis.kr)- KOSIS (Korea Statistical Information System)- 통계청을 비롯하여 여러 통계작성 기관에서 제공되고 있는 통계 정보 제공 ▶ e-나라지표 : 국가주요지표 (http://www.index.go.kr)- 국정 전문 분야에 대한 각종 국정통계에 대해 정확한 통계와 추이, 통.. 2017. 1. 7. 그리스 문자 / 표기 정리 :: Data 쿡북 그리스 문자 / 표기 정리 2017년 1월 5일 맑음 수학이나 통계를 배우다 보면 수포자들이 항상 좌절하는것이 그리스 문자다뜻은 고사하고 읽기도 힘들어 하는 경우가 많은데 잠깐 기억하자는 뜻에서 올려 본다. [출처] http://tire.egloos.com/m/10672217 2017. 1. 5. 이전 1 다음 반응형