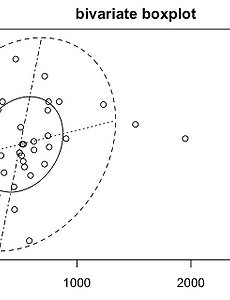
쿡북8 R을 활용한 공분산과 상관계수 이해 :: Data 쿡북 통계 공부하다보면 공분산 얘기가 많이 나온다.정리 차원에서 잠깐 끄적인다. | 공분산이란공분산(covariance)은 위키에서 다음과 같이 나와있다. 2개의 확률변수의 상관정도를 나타내는 값이다. 만약 2개의 변수 중 하나의 값이 상승하는 경향을 보일 때, 다른 값도 상승하는 경향의 상관관계에 있다면 공부산의 값은 양수가 될 것이다. 반대로 2개의 변수 중 하나의 값이 상승하는 경향을 보일 때, 다른 값이 하강하는 경향을 보인다면 공분산은 음수가 된다. 상관관계의 상승 혹은 하강하는 경향을 이해할 수는 있으나 2개의 변수의 측정 단위의 크기에 따라 달라지므로 정도를 파악하기에는 부적절하다. 그냥 쉽게 말해 A변수가 변할 때 B변수가 변하는 정도 라고 할 수 있다.이를 식으로 적으면 다음과 같다. 이다. .. 2017. 3. 12. R을 활용한 다변량 데이터 시각화 :: Data 쿡북 오늘은 R을 활용한 다변량 데이터를 시각화 하는 몇 몇 기본적인 사례를 공유한다.시각화에 대한 방법은 너무도 많고 때에 따라서 적당한 시각화를 고려해야 하기 때문에 많은 사례들을 알아두는것도 도움이 된다고 본다. | Bibrate boxplot 두 변수에 대한 boxplot을 그릴 때 사용한다.MVA 패키지에서 제공한다. 코드library(HSAUR2)library(MVA)data(USairpollution)head(USairpollution) x = USairpollution[,c(4,5)]bvbox(x, xlab="manu", ylab="popul")title("bivariate boxplot")identify(x) # identify함수는 outliers를 밝히기 위해 이용된다. 결과 | Bubbl.. 2017. 3. 6. 텍스트마이닝 - R을 활용한 웹 크롤링 및 단어 연관 분석 (KoNLP) :: Data 쿡북 2017.1.9 춥고 흐림. 수정사항 : 2017-08-18, 인코딩 관련 소스라인 추가 2017-09-11, 텍스트 마이닝 python korea 2017 에서 발표된 명사 추출 관련 자료 link , 데이터 기반의 명사 추출 기법 https://www.slideshare.net/kimhyunjoonglovit/pycon2017-koreannlp, | 들어가며 오늘은 R을 이용해서 웹 데이터를 크롤링하고, 수집된 텍스트를 기반으로 연관 분석을 하는 과정을 공유할까 한다. 참고로 웹 크롤링은 웹 사이트가 빈번하기 바뀌기 때문에 작성하는 현 시점기준의 스크립트임을 밝힌다. 혹 크롤링 대상 사이트에 변경이 있을 경우 해당 부분의 수정은 필요하다| R을 활용한 웹 크롤링오늘 해 볼 것은 1. DAUM 의 영화.. 2017. 1. 8. 텍스트마이닝 - R을 활용한 Facebook 워드 클라우드 분석 방법(wordcloud) :: Data 쿡북 2017년 1월 5일 날씨 맑음 | 들어가며지난 한해도 정리할 겸 Facebook에 작성했던 글을 한번 뽑아 보고 싶어졌다.사실 예전에 R로 워드 클라우드 그렸던 거라 기억이 가물가물해 과거에 작성했던 교육내용하고 최근 KoNLP가 0.80으로 업데이트 되었다는 소식에 전희원님의 글을 참고해 다시 뽑아봤다. ▶ KoNLP v.0.80.0 릴리즈 소식 : http://freesearch.pe.kr/archives/4520 참고로 0.80의 개선 포인트로 성능개선은 말할것도 없고, 버그 수정, 형태소 사전 추가 적용, 텍스트 전처리 플러그인 등이 추가되었다고 한다. 추후 RNN 을 연결하는 것을 생각하신다고 하니 R을 기반으로 텍스트 마이닝을 하시는 분들에게는 좋은 소식이지 않을까? | 패키지 설치와 Fac.. 2017. 1. 5. 이전 1 2 다음